.svg)


.svg)
In the previous blog post I looked at the role of catalogs in Flink SQL, the different types, and some of the quirks around their configuration and use. If you are new to Flink SQL and catalogs, I would recommend reading that post just to make sure you’re not making some of the same assumptions that I mistakenly did when looking at this for the first time.
In this article I am going to walk through the use of several different catalogs and go into a bit of depth with each to help you understand exactly what they’re doing—partly out of general curiosity, but also as an important basis for troubleshooting. I’ll let you know now: some of this goes off on tangents somewhat, but I learnt lots during it and I want to share that with you!
I’m going to cover the following areas - feel free to jump around or skip them as you prefer:
- Hive Catalog
- JDBC Catalog
- Iceberg Catalog
• Hive metastore
• DynamoDB metastore
• JDBC metastore
Why three different metastores with the Iceberg catalog? Because I found the documentation across the different projects difficult to reconcile into a consistent overall picture, so by examining multiple backends I got a proper grasp of what was going on.
Let’s get started with one of the most widely-supported and open-standard catalogs: Apache Hive, and specifically, its Metastore.
Using the Hive Catalog with Flink SQL
The Hive catalog is one of the three catalogs that are part of the Flink project. It uses the Hive Metastore to persist object definitions, so is one of the primary choices you've got for a catalog to use with Flink.
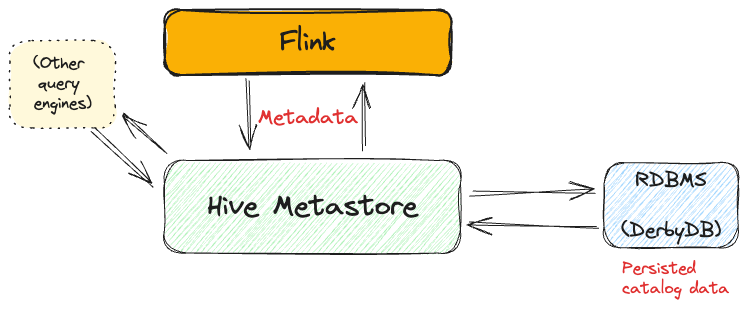
Installation and Configuration
It's important to note that whilst the Hive catalog is part of the Flink project, it's not shipped with the binaries. The docs describe the process of installing the dependencies and necessary configuration, but to someone not super-familiar with Java and Hadoop I found myself stuck quite often. In case you're in the same boat, I'm going to detail here the steps I took to get it working.
This is all on my local machine; doing the same for a production-grade deployment of Flink would probably be different. And if you're using a managed Flink service, irrelevant 😄.
The first thing to do is to make sure you've got a Hive Metastore. Fortunately Chris Riccomini has built and shared a Docker image that provides just this. It uses an embedded DerbyDB to store the metadata. As mentioned; this is just for a local setup—if you decide to take this on to real use then you'll want to make sure you're persisting the data in a proper RDBMS.
Run this to start the container which listens on port 9083:
Now we need to create a file that Flink is going to look for to tell it where to find the Hive Metastore. This is <span class="inline-code">hive-site.xml</span> and needs to go in Flink’s <span class="inline-code">./conf</span> folder (by default):
Note that <span class="inline-code">localhost:9083</span> points to the Docker container we just started. If you're using a Hive Metastore on a different host/port then amend this as needed.
Now we get to the fun bit—dependencies!
The Hive dependency is actually straightforward: download <span class="inline-code">flink-sql-connector-hive-3.1.3</span> from Maven Central into a new subfolder under your <span class="inline-code">./lib</span> folder:
This is where it gets "fun": Hadoop Dependency
Unless you have a Hadoop distribution lying around on your hard drive you're going to need to avail yourself of some JARs. There's the simple way, and the hacky way. Let's start with the hacky one.
Option 1: Slightly Hacky but light-weight
The alternative to a full Hadoop download which we'll see below (and resulting JAR clashes as seen with FLINK-33358) is to just download the JARs that Hive seems to want and make those available. I've identified these by trial-and-error because I was offended by needing such a heavy-weight download <span class="inline-code">¯\_(ツ)_/¯</span>. Download them directly into the <span class="inline-code">./lib/hive</span> folder that we created above:
Option 2: The Proper (but bloated) Option
Download and extract 600MB Hadoop tar file:
Set the <span class="inline-code">HADOOP_CLASSPATH</span>. Something you might miss from the docs (I did) is that what's quoted:
This actually executes the <span class="inline-code">hadoop</span> binary with the <span class="inline-code">classpath</span> command, and sets the output as the environment variable <span class="inline-code">HADOOP_CLASSPATH</span>. In effect it's doing this:
and taking that output to set as the environment variable that the Hive code in Flink will use. Unless you've gone ahead and actually installed Hadoop, you'll need to specify the binary's absolute path to use it:
You'll notice I'm using <span class="inline-code">$( )</span> instead of <span class="inline-code">` `</span> to enclose the <span class="inline-code">hadoop</span> call because to me it's more readable and less ambiguous—I read the docs as meaning you just had to put the Hadoop classpath in the place of <span class="inline-code">hadoop classpath</span>, not that it was an actual command to run.
If you're using 1.18 then because of [FLINK-33358] Flink SQL Client fails to start in Flink on YARN - ASF JIRA you'll need to apply this small PR to your <span class="inline-code">sql-client.sh</span> before running the SQL Client.
SQL Client with the Hive Catalog
With our dependencies installed and configured, and a Hive Metastore instance running, we're ready to go and use our Hive catalog. Launch the SQL Client:
If you're using <span class="inline-code">HADOOP_CLASSPATH</span> make sure you set it in the context of the shell session that you launch the SQL Client in.
From the Flink SQL prompt you can create the catalog:
Set the catalog to the active one:
List databases:
Create a new database & use it:
The <span class="inline-code">SHOW CURRENT</span> command is useful to orientate yourself in the session:
To show that the persistence of the catalog metadata in Hive Metastore is working let's go and create a table:
We'll query it, just to make sure things are working:
Now restart the session:
Because we're using the Hive catalog and not the in-memory one, we should see the database (<span class="inline-code">new_db</span>) and table (<span class="inline-code">foo</span>) still present:
Oh noes! It didn't work! 🙀 Or did it? 😼
I mentioned Catalog Stores in my first blog post, and I've not defined one—meaning that the catalog definition is not persisted between sessions. If I define the catalog again:
Then I find that the catalog's metadata is still present, as it should be!
In this sense, when we create a catalog in Flink it's more like creating a connection. Once that connection is created, whatever metadata is stored the other side of it becomes available to Flink.
So that's using the Hive catalog with Flink. You can skip over the next section if you want, but if you're like me and curious as to what's happening behind the scenes then keep reading.
Sidenote: Digging a bit Deeper into the Hive Metastore
Here's what we'll see on successful connection from the SQL Client to the Hive Metastore in the logs (<span class="inline-code">flink-rmoff-sql-client-asgard08.log</span>):
We can inspect the network traffic between Flink and Hive using <span class="inline-code">tcpdump</span>. Since the Hive Metastore is on Docker, we'll use another container to help here. Create a <span class="inline-code">tcpdump</span> docker image:
With this we can capture details of the communication between Flink and the Hive Metastore:
Hive metastore uses the Thrift protocol to communicate with clients, and by loading the resulting <span class="inline-code">pcap</span> file into Wireshark we can inspect this traffic in more detail. Here we see the creation of a table called <span class="inline-code">foo_new2</span> in the <span class="inline-code">new_db</span> database:
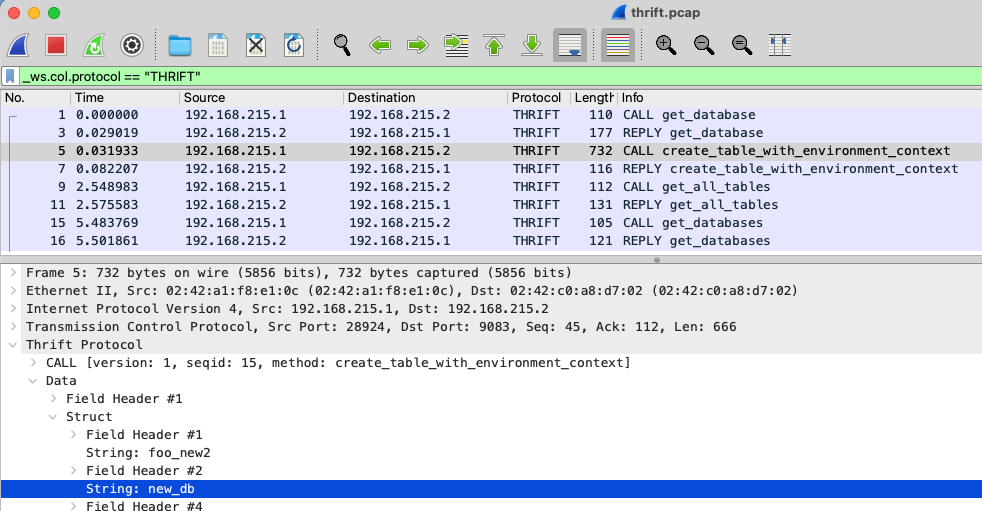
Of course, none of this is actually necessary for simply using a catalog with Flink—but I found it useful for mapping out in my mind what's actually happening.
What does the Hive catalog look like when storing Parquet data in S3 (MinIO) from Flink?
OK, back to the main storyline. We've now got a Hive catalog working, persisting the metadata about a definition-only table. What do I mean by a definition-only table? Well it's completely self-contained; there is no real data, just <span class="inline-code">datagen</span>:
Let's now add in something more realistic, and understand how we can write data from Flink to a table whose data actually exists somewhere. We’ll store the data on MinIO, which is an S3-compatible object store that you can run locally, and write it in the widely-adopted Apache Parquet column-oriented file format.
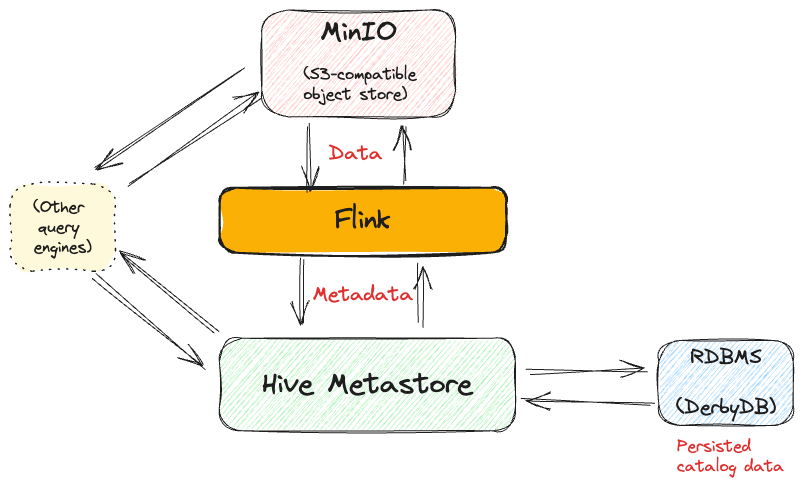
Setup
First we need to add the Parquet format to the available JARs:
Now we'll set up the S3 bit, for which we're using MinIO and will need Flink's S3 support. Run MinIO using Docker:
Then provision a bucket:
Flink's S3 plugin is included in the Flink distribution but needs to be added to the <span class="inline-code">./plugins</span> folder to be available for us:
Finally, add the required configuration to <span class="inline-code">./conf/flink-conf.yaml</span>:
[Re]start your Flink cluster, and launch the SQL Client.
Using Parquet and S3 from Flink
Declare the Hive catalog connection again, and create a new database within it:
Now we'll create a table that's going to use filesystem persistence for its data, which will be written in Parquet format:
Add some data to the table:
Using MinIO's <span class="inline-code">mc</span> CLI tool we can see the table data written:
Now let's look at the catalog. I'm using the same Hive Metastore container as we launched above, which stores the data in an DerbyDB. We can copy this out of the container and onto our local machine for inspection using the <span class="inline-code">ij</span> tool:
<span class="inline-code">ij</span> is a bit clunky when it comes to pretty output (e.g. rows are very wide and not helpfully formatted based on the width of the data) so let's use DBeaver to speed things up and look at the table we created. Helpfully it can also infer the Entity-Relationship diagram automagically to aid our comprehension of the data that the metastore holds:
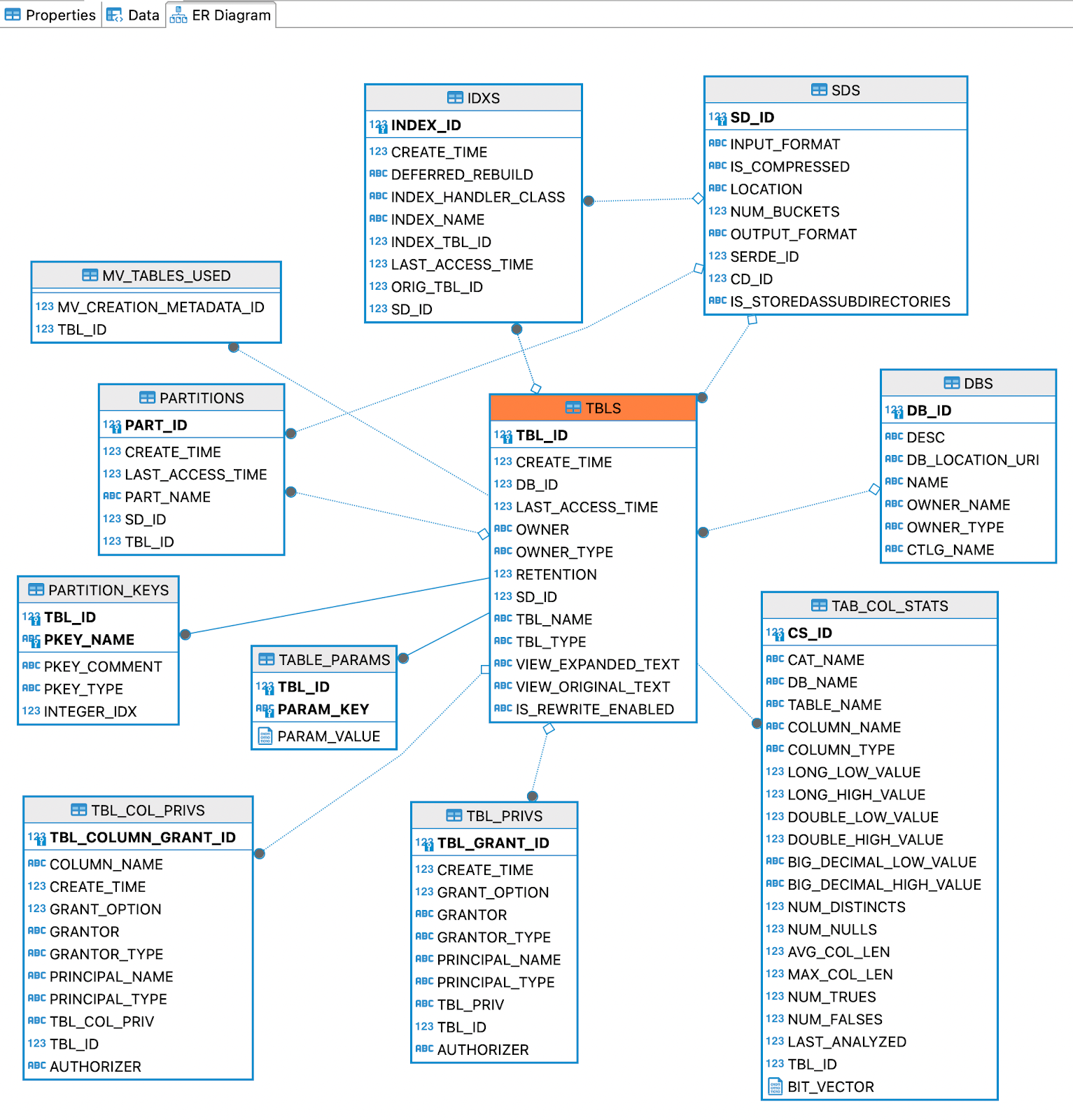
Here's the table that we created:
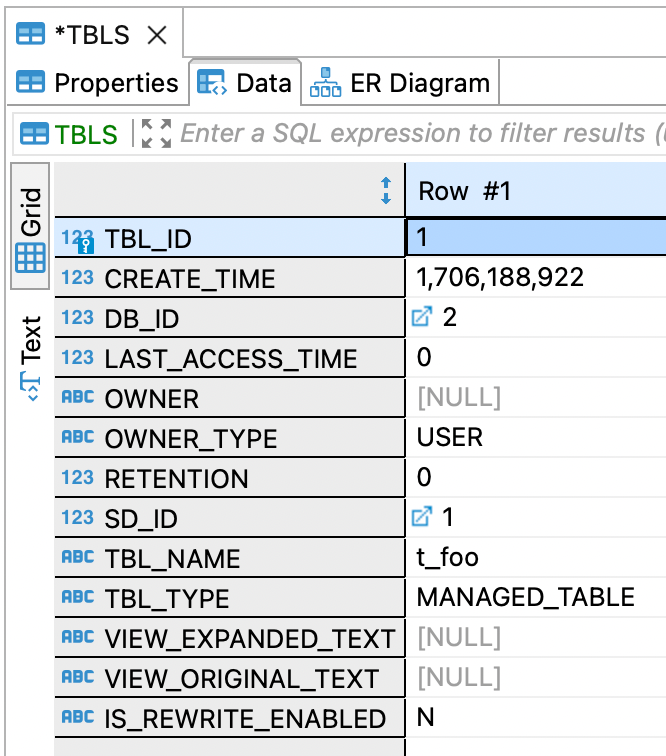
I wonder where things like the warehouse path are stored? Based on the above diagram we can see <span class="inline-code">TABLE_PARAMS</span> so let's check that out:
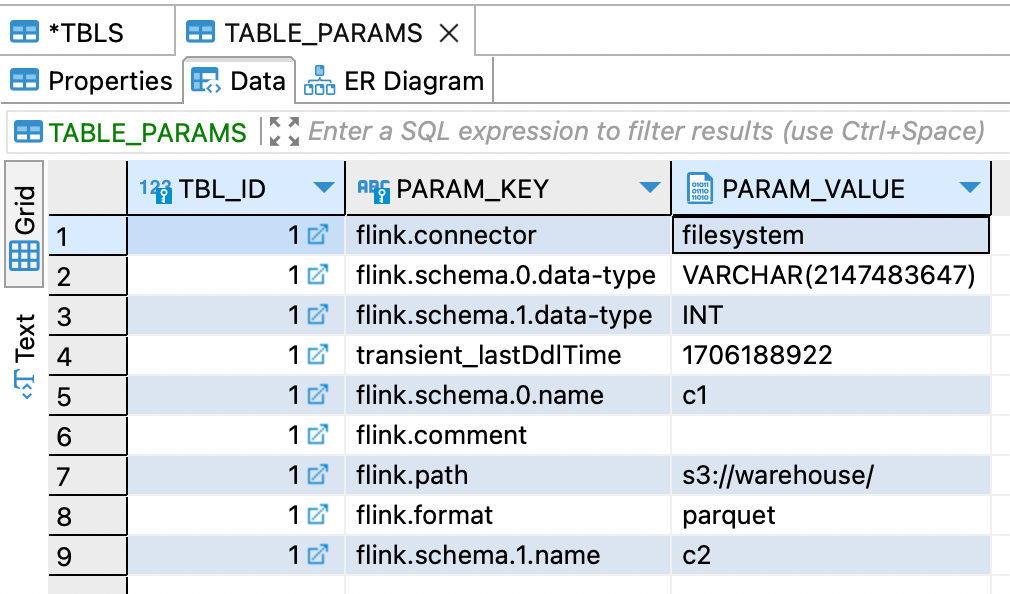
Here's all our metadata for the table, including the location of data on disk, its format, and so on.
Phew! 😅 That was the Hive Catalog. There's just one more catalog that's provided with Flink before we get onto some of the other ones. Without further ado, let's look at the JDBC Catalog.
The Flink JDBC Catalog
The JDBC Catalog in Flink is a bit of an odd one if you're coming to it expecting a catalog that holds object definitions in Flink of your creation. What the JDBC catalog does is expose the existing objects and their data of a target database to Flink. Which is pretty neat—it's just not what you might assume it does. With that in mind, let's see how it works.
Installation and Configuration
Fortunately, the dependencies for the JDBC catalog are a lot simpler than Hive's. As with the Hive connector you need to download the JDBC connector separately since it's not bundled with the Flink distribution. You also need the JDBC driver of the database to which you want to connect—the docs have a useful reference to the download links for these.
As of the end of January 2024, Flink 1.18.1 has no released version of the JDBC connector, but with a release vote underway I'd expect that to change soon. The example I've done here is using the third release candidate (RC3) of the JDBC connector.
So, let's download both the required JARs into a new folder under <span class="inline-code">./lib</span>:
We also need a database to use. I'm using a vanilla Postgres database in a Docker container:
Let’s create a table with some data in it, with the <span class="inline-code">psql</span> CLI tool:
Now we’ll hook this up to Flink.
Using the JDBC Catalog in Flink
With the Flink JDBC connector JAR and JDBC driver in place, we can launch the Flink cluster and SQL Client:
From the SQL prompt let's create the JDBC Catalog:
Now we can select the catalog as the current one and look at the tables that are defined in it. These are the tables of the database to which we connected above. Note that Flink doesn’t use the concept of schemas so as noted in the docs the Postgres schema (<span class="inline-code">public</span> in this example) is prepended to the table name shown in Flink.
Querying the Postgres tables from Flink works as you'd expect. Make sure you quote with backticks object names as needed (e.g. the <span class="inline-code">public.</span> prefix on the Postgres table names):
If we were to change that data over in Postgres:
And run the same query again in Flink we can see it correctly shows the new data (as you would expect):
When it comes to writing from Flink to the JDBC catalog, we can only write data. Per the documentation, the creation of new objects (such as tables) isn’t supported:
But what we can do is write data (as opposed to metadata) back to the database:
Which we then see in Postgres:
So, there we have it. Reading and writing from a database with Flink via the JDBC Connector and its JDBC Catalog! This is going to be pretty handy, whether we want to analyse the data, or use it for joins with data coming from other sources, such as Apache Kafka or other streams of data.
Third-Party Flink Catalogs: Apache Iceberg
Flink can be used with many different technologies, including the open-table formats. Each of these implement a Flink catalog so that you can access and use their objects from Flink directly. Here I'll show you Apache Iceberg's Flink catalog, with three different metastores, (or backing catalogs, however you like to think of it). Why three? Well, to get my head around what was Iceberg, what was Flink, and what was metastore, I needed to try multiple options to understand the pattern.
In all of these I'm using MinIO for storage, which is an S3-compatible object store that can be run locally.
Flink, Iceberg, and Hive Metastore
This one was a lot of fun to figure out. You can perhaps put a hefty number of air-quotes around that innocently-italicised <span class="inline-code">fun</span>. 😉 I'm going to dig into the deluge of dastardly debugging in a subsequent blog—for now we'll just look at things when they go right.
Since the focus of my efforts is to understand how Flink SQL can be used by a non-Java person, I'm also making the assumption that they don't have a Hadoop or Hive installation lying around and want to run as much of this standalone locally. So as above—where we use the Hive Metastore as a Flink catalog directly—I'm using the standalone Hive metastore Docker image. I've bundled this up into a GitHub repository with Flink and Iceberg if you want to try this out.
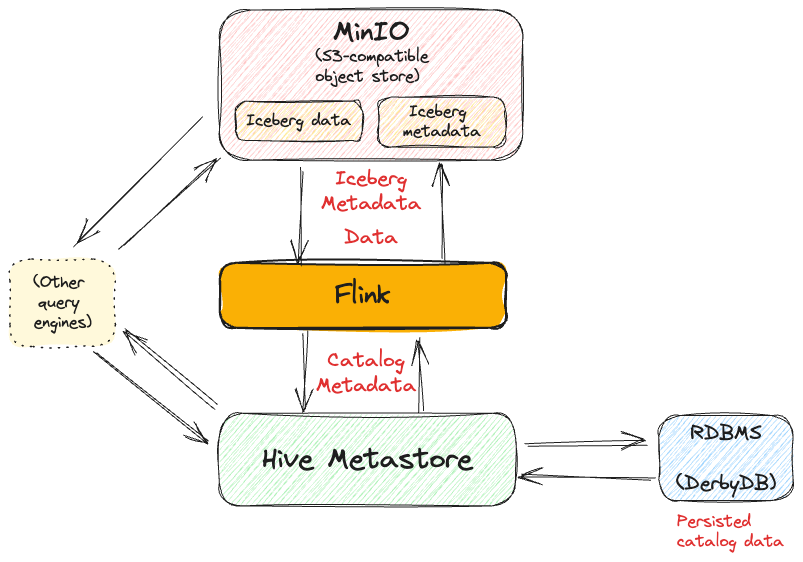
The main thing to be aware of is that it's not just your Flink instance that will write to MinIO (S3), but the Hive Metastore too (when you create a database, for example). Therefore you need to add the S3 endpoint and authentication details to the hive-site.xml on the Hive Metastore too—not just Flink:
The Flink hive-site.xml needs this too, along with the details of where the Hive Metastore can be found:
With the Hive configuration done, add the necessary JAR files to your Flink <span class="inline-code">./lib</span> folder. You can use subfolders if you want to make it easier to track these; the classpath will recurse through them.
Once you've launched Flink, MinIO, and the Hive Metastore, you can go ahead and create the Iceberg catalog in Flink from the Flink SQL Client:
There are a couple of important points to be aware of here. Firstly, the <span class="inline-code">warehouse</span> path defines where both the table data and metadata is held. That's a storage choice made by the Iceberg format, enhancing its portability and interoperability by not having its metadata tied into a particular backend.
The second thing to note in the catalog configuration is that it's incomplete; we're pointing to a second set of configuration held in the <span class="inline-code">hive-site.xml</span> file using the <span class="inline-code">hive-conf-dir</span> parameter. This is where, as I mentioned above, the authentication and connection details for S3 are held. We could even move <span class="inline-code">warehouse</span> into this and out of the <span class="inline-code">CREATE CATALOG</span> DDL, but I prefer it here for clarity.
Now we can create a database within this catalog, and tell Flink to use it for subsequent commands:
Let's go ahead and create an Iceberg table and add some data:
To complete the end-to-end check, we can read the data back:
Let's look at the data that's been written to MinIO:
You can see here in practice how we have both <span class="inline-code">/data</span> and <span class="inline-code">/metadata</span>. The metadata files hold, unsurprisingly, metadata:
Whilst the data on disk itself is just a parquet file, which we can validate using DuckDB to read it once we've fetched it from MinIO:
How does Flink know to go to the bucket called <span class="inline-code">warehouse</span> and path <span class="inline-code">db_rmoff.db/t_foo/[…]</span> to find the data and metadata for the table? That's where the Catalog comes in. The Hive metastore—in this case—holds the magical metadata of this relationship, which we can see if we query the embedded DerbyDB:
Flink, Iceberg, and DynamoDB Metastore
This permutation is obviously—given the use of DynamoDB—designed for when you're running Flink on AWS, perhaps with EMR. My thanks to Chunting Wu who published an article and corresponding GitHub repo that shows how to get this up and running.
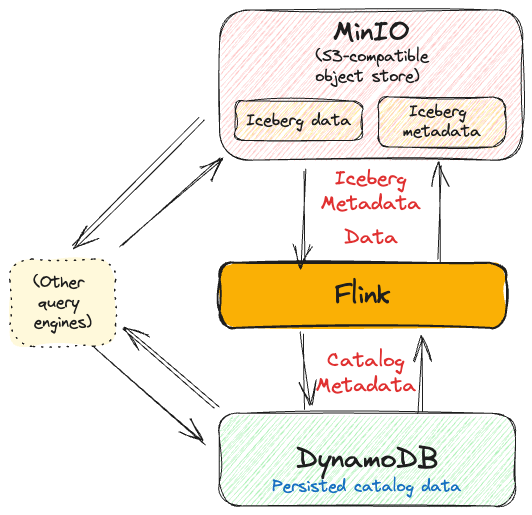
From the SQL Client, we create the Iceberg catalog with DynamoDB as the metastore. Note the use of <span class="inline-code">catalog-impl</span> rather than <span class="inline-code">catalog-type</span>.
Now create a database in the new catalog and set it as the current one:
With that done we can create a table and some data in it:
Check the data has been persisted:
This all looks good! As you'd expect, the data and metadata written to disk is the same as above when we use the Hive Metastore—because all we're changing out here is the metastore layer, everything else is the same.
Whilst the Hive metastore used a relational database to store metadata about the Iceberg table, we can see how the same set of data is stored in DynamoDB by using dynamodb-admin:
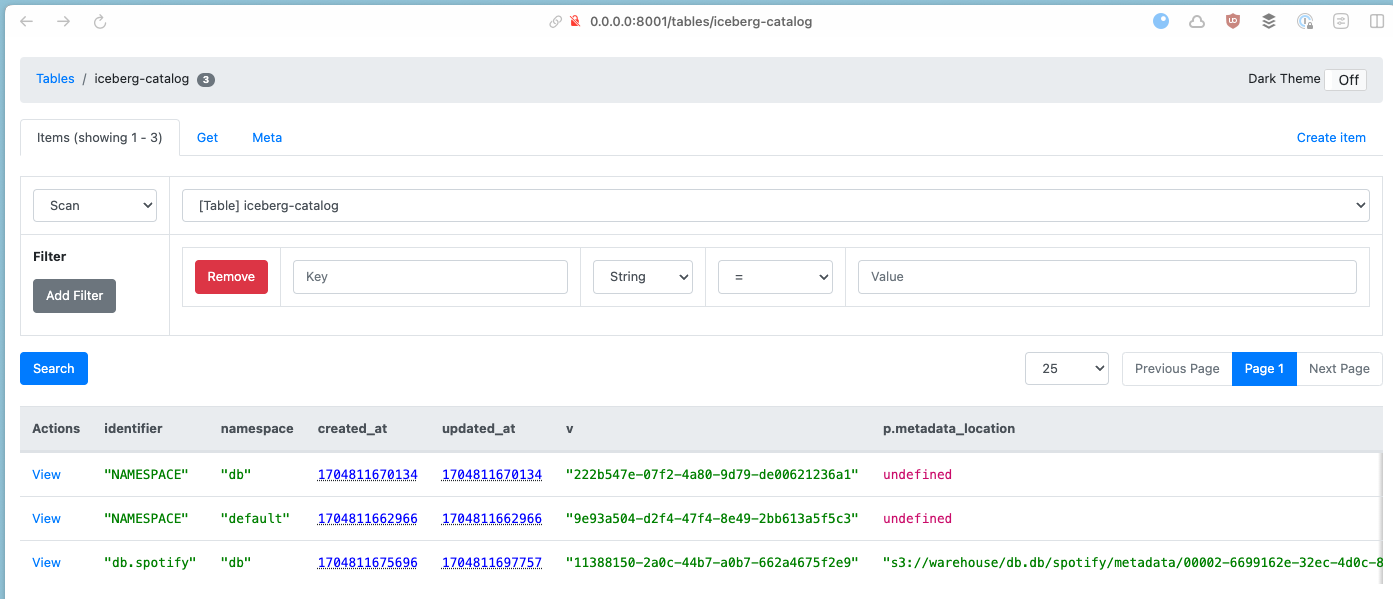
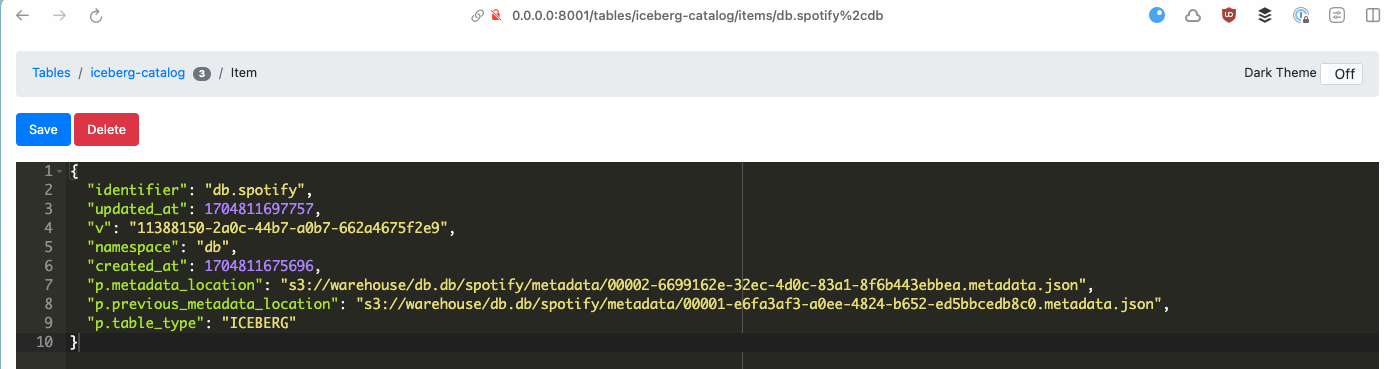
Flink, Iceberg, and JDBC Metastore
Iceberg actually supports 9 catalog types, but don't worry—I'm not going to go through each one 😅. We've already got a handle on the pattern here:
- Flink tables are written with both metadata and data to storage (MinIO in our case).
- Metadata about those tables is held in a Catalog metastore which is persisted somewhere specific to that metastore.
The JDBC Catalog uses a JDBC-compatible database - in the example below, Postgres.
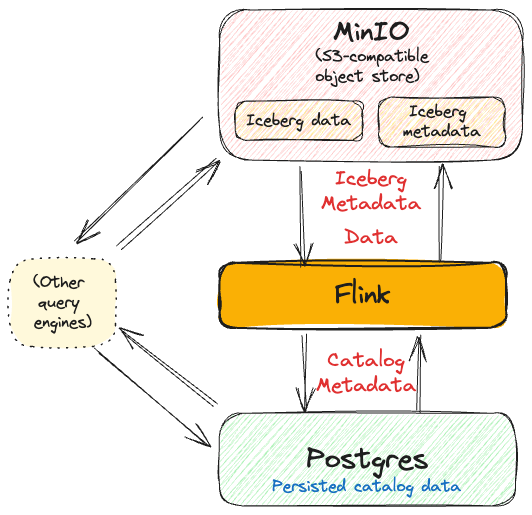
In terms of dependencies you need
- Flink S3 plugin
- JDBC Driver for your database
- Iceberg JARs
- AWS S3 JARs
You can find the full example on GitHub.
I set the credentials for the S3 storage as environment variables—there is probably a better way to do this.
Let's go ahead and create the catalog:
You know the drill by now—create the database, set it as current, create the table and populate it:
The Iceberg table written to MinIO (S3) is as before - a mixture of <span class="inline-code">/data</span> and <span class="inline-code">/metadata</span>. The difference this time round is where we're storing the catalog. Querying Postgres shows us the metastore tables:
And the table's metadata itself:
In Conclusion…
If you’ve stuck with me this far, well done! 🙂 My aim was not to put you through the same pain as I had in traversing this, but to summarise the key constants and variables when using the different components and catalogs.
Stay tuned to this blog for my next post which will be a look at some of the troubleshooting techniques that can be useful when exploring Flink SQL.
Fun fact: if you use Decodable’s fully managed Flink platform you don’t ever have to worry about catalogs—we handle it all for you!






.svg)